与其他 location 配合
location = /app/test_queue {
content_by_lua_block {
local start_time = ngx.now()
local res1 = ngx.location.capture_multi( {
{"/sum", {args={a=3, b=8}}}
})
local res2 = ngx.location.capture_multi( {
{"/subduction", {args={a=3, b=8}}}
})
ngx.say("status:", res1.status, " response:", res1.body)
ngx.say("status:", res2.status, " response:", res2.body)
ngx.say("time used:", ngx.now() - start_time)
}
}
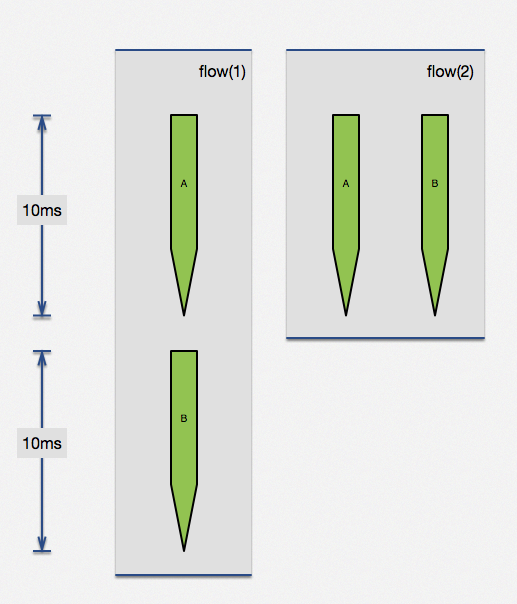
利用 ngx.location.capture_multi 函数,直接完成了两个子请求并行执行。当两个请求没有相互依赖,这种方法可以极大提高查询效率。两个无依赖请求,各自是 100ms,顺序执行需要 200ms,但通过并行执行可以在 100ms 完成两个请求。实际生产中查询时间可能没这么规整,但思想大同小异,这个特性是很有用的。
获取 uri 参数
获取请求 uri 参数
首先看一下官方 API 文档,获取一个 uri 有两个方法:ngx.req.get_uri_args、ngx.req.get_post_args,前者来自 uri 请求参数,而后者来自 post 请求内容。
获取请求body
获取请求body
原来我们还需要添加指令 lua_need_request_body,才能get_body_data()
http {
server {
listen 80;
# 默认读取 body
lua_need_request_body on;
location /test {
content_by_lua_block {
local data = ngx.req.get_body_data()
ngx.say("hello ", data)
}
}
}
}
如果你只是某个接口需要读取 body(并非全局行为),那么这时候也可以显示调用 ngx.req.read_body() 接口,参看下面示例:
http {
server {
listen 80;
location /test {
content_by_lua_block {
ngx.req.read_body()
local data = ngx.req.get_body_data()
ngx.say("hello ", data)
}
}
}
}
body 偶尔读取不到?
ngx.req.get_body_data() 读请求体,会偶尔出现读取不到直接返回 nil 的情况。
如果请求体尚未被读取,请先调用 ngx.req.read_body (或打开 lua_need_request_body 选项强制本模块读取请求体,此方法不推荐)。
如果请求体已经被存入临时文件,请使用 ngx.req.get_body_file 函数代替。
输出响应体
ngx.say 与 ngx.print 均为异步输出
location /test2 {
content_by_lua_block {
ngx.say("hello")
ngx.flush() -- 显式的向客户端刷新响应输出
ngx.sleep(3)
ngx.say("the world")
}
}
如何优雅处理响应体过大的输出
如果响应体比较小,这时候相对就比较随意。但是如果响应体过大(例如超过 2G),是不能直接调用 API 完成响应体输出的。响应体过大,分两种情况:
- 输出内容本身体积很大,例如超过 2G 的文件下载
- 输出内容本身是由各种碎片拼凑的,碎片数量庞大,例如应答数据是某地区所有人的姓名
第①个情况,要利用 HTTP 1.1 特性 CHUNKED 编码来完成
location /test {
content_by_lua_block {
-- ngx.var.limit_rate = 1024*1024
local file, err = io.open(ngx.config.prefix() .. "data.db","r")
if not file then
ngx.log(ngx.ERR, "open file error:", err)
ngx.exit(ngx.HTTP_SERVICE_UNAVAILABLE)
end
local data
while true do
data = file:read(1024)
if nil == data then
break
end
ngx.print(data)
ngx.flush(true)
end
file:close()
}
}
第②个情况,其实就是要利用 ngx.print 的特性了,它的输入参数可以是单个或多个字符串参数,也可以是 table 对象。
参考官方示例代码:
local table = {
"hello, ",
{"world: ", true, " or ", false,
{": ", nil}}
}
ngx.print(table)
将输出:
hello, world: true or false: nil
日志输出
标准日志输出
OpenResty 的标准日志输出原句为 ngx.log(log_level, ...) ,几乎可以在任何 ngx_lua 阶段进行日志的输出。
有关 Nginx 的日志级别,请看下表:
- ngx.STDERR – 标准输出
- ngx.EMERG – 紧急报错
- ngx.ALERT – 报警
- ngx.CRIT – 严重,系统故障,触发运维告警系统
- ngx.ERR – 错误,业务不可恢复性错误
- ngx.WARN – 告警,业务中可忽略错误
- ngx.NOTICE – 提醒,业务比较重要信息
- ngx.INFO – 信息,业务琐碎日志信息,包含不同情况判断等
- ngx.DEBUG – 调试
网络日志输出
lua-resty-logger-socket 的目标是替代 Nginx 标准的 ngx_http_log_module 以非阻塞 IO 方式推送 access log 到远程服务器上。对远程服务器的要求是支持 syslog-ng 的日志服务。
例举几个好处:
- 基于 cosocket 非阻塞 IO 实现
- 日志累计到一定量,集体提交,增加网络传输利用率
- 短时间的网络抖动,自动容错
- 日志累计到一定量,如果没有传输完毕,直接丢弃
- 日志传输过程完全不落地,没有任何磁盘 IO 消耗
如何发起新 HTTP 请求
利用 proxy_pass
利用 proxy_pass 完成 HTTP 接口访问的成熟配置+调用方法。 借用 nginx 周边成熟组件力量,为了发起一个 HTTP 请求,我们需要绕好几个弯子,甚至还有可能踩到坑(upstream 中长连接的细节处理),显然没有足够优雅,所以我们继续看下一章节。
利用 cosocket
重点解释: ① 引用 resty.http 库资源,它来自 github https://github.com/pintsized/lua-resty-http。 ② 参考 resty-http 官方 wiki 说明,我们可以知道 request_uri 函数完成了连接池、HTTP 请求等一系列动作。
访问有授权验证的 Redis
-- 请注意这里 auth 的调用过程
local count
count, err = red:get_reused_times()
if 0 == count then
ok, err = red:auth("password")
if not ok then
ngx.say("failed to auth: ", err)
return
end
elseif err then
ngx.say("failed to get reused times: ", err)
return
end
如果当前连接不是从内建连接池中获取的,该方法总是返回 0 ,也就是说,该连接还没有被使用过。如果连接来自连接池,那么返回值永远都是非零。所以这个方法可以用来确认当前连接是否来自池子。
对于 Redis 授权,实际上只需要建立连接后,首次认证一下,后面只需直接使用即可。换句话说,从连接池中获取的连接都是经过授权认证的,只有新创建的连接才需要进行授权认证。所以大家就看到了 count, err = red:get_reused_times() 这段代码,并有了下面 if 0 == count then 的判断逻辑。
pipeline 压缩请求数量

很庆幸 Redis 早就为我们准备好了这道菜,就等着我们吃了,这道菜就叫 pipeline。pipeline 机制将多个命令汇聚到一个请求中,可以有效减少请求数量,减少网络延时。下面是对比使用 pipeline 的一个例子:
location /withpipeline {
content_by_lua_block {
local redis = require "resty.redis"
local red = redis:new()
red:set_timeout(1000) -- 1 sec
-- or connect to a unix domain socket file listened
-- by a redis server:
-- local ok, err = red:connect("unix:/path/to/redis.sock")
local ok, err = red:connect("127.0.0.1", 6379)
if not ok then
ngx.say("failed to connect: ", err)
return
end
red:init_pipeline()
red:set("cat", "Marry")
red:set("horse", "Bob")
red:get("cat")
red:get("horse")
local results, err = red:commit_pipeline()
if not results then
ngx.say("failed to commit the pipelined requests: ", err)
return
end
for i, res in ipairs(results) do
if type(res) == "table" then
if not res[1] then
ngx.say("failed to run command ", i, ": ", res[2])
else
-- process the table value
end
else
-- process the scalar value
end
end
-- put it into the connection pool of size 100,
-- with 10 seconds max idle time
local ok, err = red:set_keepalive(10000, 100)
if not ok then
ngx.say("failed to set keepalive: ", err)
return
end
}
}
json 解析的异常捕获
local json = require("cjson")
local function _json_decode(str)
return json.decode(str)
end
function json_decode( str )
local ok, t = pcall(_json_decode, str)
if not ok then
return nil
end
return t
end
如果需要在 Lua 中处理错误,必须使用函数 pcall(protected call)来包装需要执行的代码。 pcall 接收一个函数和要传递给后者的参数,并执行,执行结果:有错误、无错误;返回值 true 或者或 false, errorinfo。pcall 以一种”保护模式”来调用第一个参数,因此 pcall 可以捕获函数执行中的任何错误。有兴趣的同学,请更多了解下 Lua 中的异常处理。
另外,可以使用 CJSON 2.1.0,该版本新增一个 cjson.safe 模块接口,该接口兼容 cjson 模块,并且在解析错误时不抛出异常,而是返回 nil。
local json = require("cjson.safe")
local str = [[ {"key:"value"} ]]
local t = json.decode(str)
if t then
ngx.say(" --> ", type(t))
end
稀疏数组
如果把 data 的数组下标修改成 5 ,那么这个 json.encode 就会是成功的。 结果是:[1, 2,null, null, 99]
为什么下标是 1000 就失败呢?实际上这么做是 cjson 想保护你的内存资源。她担心这个下标过大直接撑爆内存(贴心小棉袄啊)。如果我们一定要让这种情况下可以 encode,就要尝试 encode_sparse_array API 了。有兴趣的同学可以自己试一试。我相信你看过有关 cjson 的代码后,就知道 cjson 的一个简单危险防范应该是怎样完成的。
编码为 array 还是 object
首先大家请看这段源码:
-- http://www.kyne.com.au/~mark/software/lua-cjson.php
-- version: 2.1 devel
local json = require("cjson")
ngx.say("value --> ", json.encode({dogs={}}))
输出结果
value --> {"dogs":{}}
注意看下 encode 后 key 的值类型,”{}” 代表 key 的值是个 object,”[]” 则代表 key 的值是个数组。对于强类型语言(C/C++, Java 等),这时候就有点不爽。因为类型不是他期望的要做容错。对于 Lua 本身,是把数组和字典融合到一起了,所以他是无法区分空数组和空字典的。
-- 内容节选lua-cjson-2.1.0.2/tests/agentzh.t
=== TEST 1: empty tables as objects
--- lua
local cjson = require "cjson"
print(cjson.encode({}))
print(cjson.encode({dogs = {}}))
--- out
{}
{"dogs":{}}
=== TEST 2: empty tables as arrays
--- lua
local cjson = require "cjson"
cjson.encode_empty_table_as_object(false)
print(cjson.encode({}))
print(cjson.encode({dogs = {}}))
--- out
[]
{"dogs":[]}
执行阶段概念
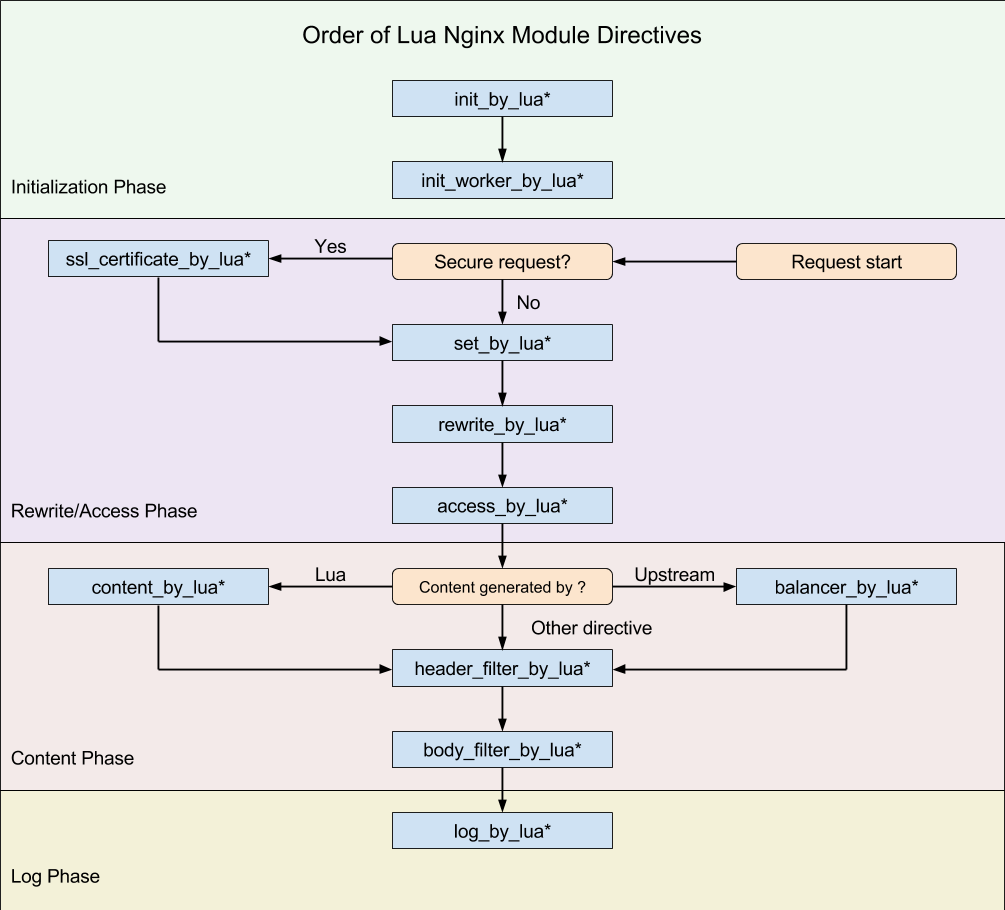
这样我们就可以根据我们的需要,在不同的阶段直接完成大部分典型处理了。
- set_by_lua*: 流程分支处理判断变量初始化
- rewrite_by_lua*: 转发、重定向、缓存等功能(例如特定请求代理到外网)
- access_by_lua*: IP 准入、接口权限等情况集中处理(例如配合 iptable 完成简单防火墙)
- content_by_lua*: 内容生成
- header_filter_by_lua*: 响应头部过滤处理(例如添加头部信息)
- body_filter_by_lua*: 响应体过滤处理(例如完成应答内容统一成大写)
- log_by_lua*: 会话完成后本地异步完成日志记录(日志可以记录在本地,还可以同步到其他机器)
不同的阶段,有不同的处理行为,这是 OpenResty 的一大特色。学会它,适应它,会给你打开新的一扇门。这些东西不是 OpenResty 自身所创,而是 Nginx module 对外开放的处理阶段。
正确的记录日志
看过本章第一节的同学应该还记得,log_by_lua* 是一个请求经历的最后阶段。由于记日志跟应答内容无关,Nginx 通常在结束请求之后才更新访问日志。由此可见,如果我们有日志输出的情况,最好统一到 log_by_lua* 阶段。如果我们把记日志的操作放在 content_by_lua* 阶段,那么将线性的增加请求处理时间。
sleep
在 OpenResty 里面选择使用库的时候,有一个基本的原则:尽量使用 OpenResty 的库函数,尽量不用 Lua 的库函数,因为 Lua 的库都是同步阻塞的。 lua-nginx-module 的文档
定时任务
从示例代码中我们可以看到,ngx.timer.at 创建的回调是一次性的。如果要实现“定期”运行,需要在回调函数中重新创建 timer 才行。不过当前主线上的 OpenResty 已经引入了新的 ngx.timer.every 接口,允许直接创建定期执行的 timer。
需要特别注意的是:有一些 ngx_lua 的 API 不能在这里调用,比如子请求、ngx.req.*和向下游输出的 API(ngx.print、ngx.flush 之类),原因是这些调用需要依赖具体的请求。但是 ngx.timer.at 自身的运行,与当前的请求并没有关系的。
再说一遍,ngx.timer.at 的执行是在独立的协程里完成的。千万不能忽略这一点。
禁止某些终端访问
init_by_lua_block {
local iputils = require("resty.iputils")
iputils.enable_lrucache()
local whitelist_ips = {
"127.0.0.1",
"10.10.10.0/24",
"192.168.0.0/16",
}
-- WARNING: Global variable, recommend this is cached at the module level
-- https://github.com/openresty/lua-nginx-module#data-sharing-within-an-nginx-worker
whitelist = iputils.parse_cidrs(whitelist_ips)
}
access_by_lua_block {
local iputils = require("resty.iputils")
if not iputils.ip_in_cidrs(ngx.var.remote_addr, whitelist) then
return ngx.exit(ngx.HTTP_FORBIDDEN)
end
}
请求返回后继续执行
local response, user_stat = logic_func.get_response(request)
ngx.say(response)
ngx.eof()
if user_stat then
local ret = db_redis.update_user_data(user_stat)
end
没错,最关键的一行代码就是ngx.eof(),它可以即时关闭连接,把数据返回给终端,后面的数据库操作还会运行。比如上面代码中的
local response, user_stat = logic_func.get_response(request)
运行了 0.1 秒,而
db_redis.update_user_data(user_stat)
运行了 0.2 秒,在没有使用 ngx.eof() 之前,终端感知到的是 0.3 秒,而加上 ngx.eof() 之后,终端感知到的只有 0.1 秒。
需要注意的是,你不能任性的把阻塞的操作加入代码,即使在 ngx.eof()之后。 虽然已经返回了终端的请求,但是,Nginx 的 worker 还在被你占用。所以在 keep alive 的情况下,本次请求的总时间,会把上一次 eof() 之后的时间加上。 如果你加入了阻塞的代码,Nginx 的高并发就是空谈。
调试
我们在做一个操作后,就把结果记录到 Nginx 的 error.log 里面,等级是 warn。在生产环境下,日志等级默认为 error,在我们需要详细日志的时候,把等级调整为 warn 即可。在我们的实际使用中,我们会把一些很少发生的重要事件,做为 error 级别记录下来,即使它并不是 Nginx 的错误。
如何引用第三方 resty 库
OpenResty 引用第三方 resty 库非常简单,只需要将相应的文件拷贝到 resty 目录下即可。 我们以 resty.http ( pintsized/lua-resty-http) 库为例。 只要将 lua-resty-http/lib/resty/ 目录下的 http.lua 和 http_headers.lua 两个文件拷贝到 /usr/local/openresty/lualib/resty 目录下即可(假设你的 OpenResty 安装目录为 /usr/local/openresty)。